01
GPU Farms / Neo-clouds
Maximize GPU ROI with faster data access for shared training clusters, low-latency model serving, and multi-tenant infrastructure.
High-performance caching infrastructure for large-scale AI training and inference workloads.
Varnish ensures your GPUs always have fast access to the data they need — reducing wait times, cutting unnecessary data transfer costs, and helping you get more out of your investment.
Used in production by Fortune 500s, broadcasters, SaaS platforms, and tech infrastructure leaders.




GPU clusters scale faster than data delivery infrastructure can keep up. The bottleneck is no longer compute availability — it's how fast data reaches GPUs.
Traditional AI storage solutions prioritizes performance, but at high cost and with less flexibility. Object storage prioritizes cost and scale, but introduces latency, throughput, and compatibility problems. Varnish bridges that gap.
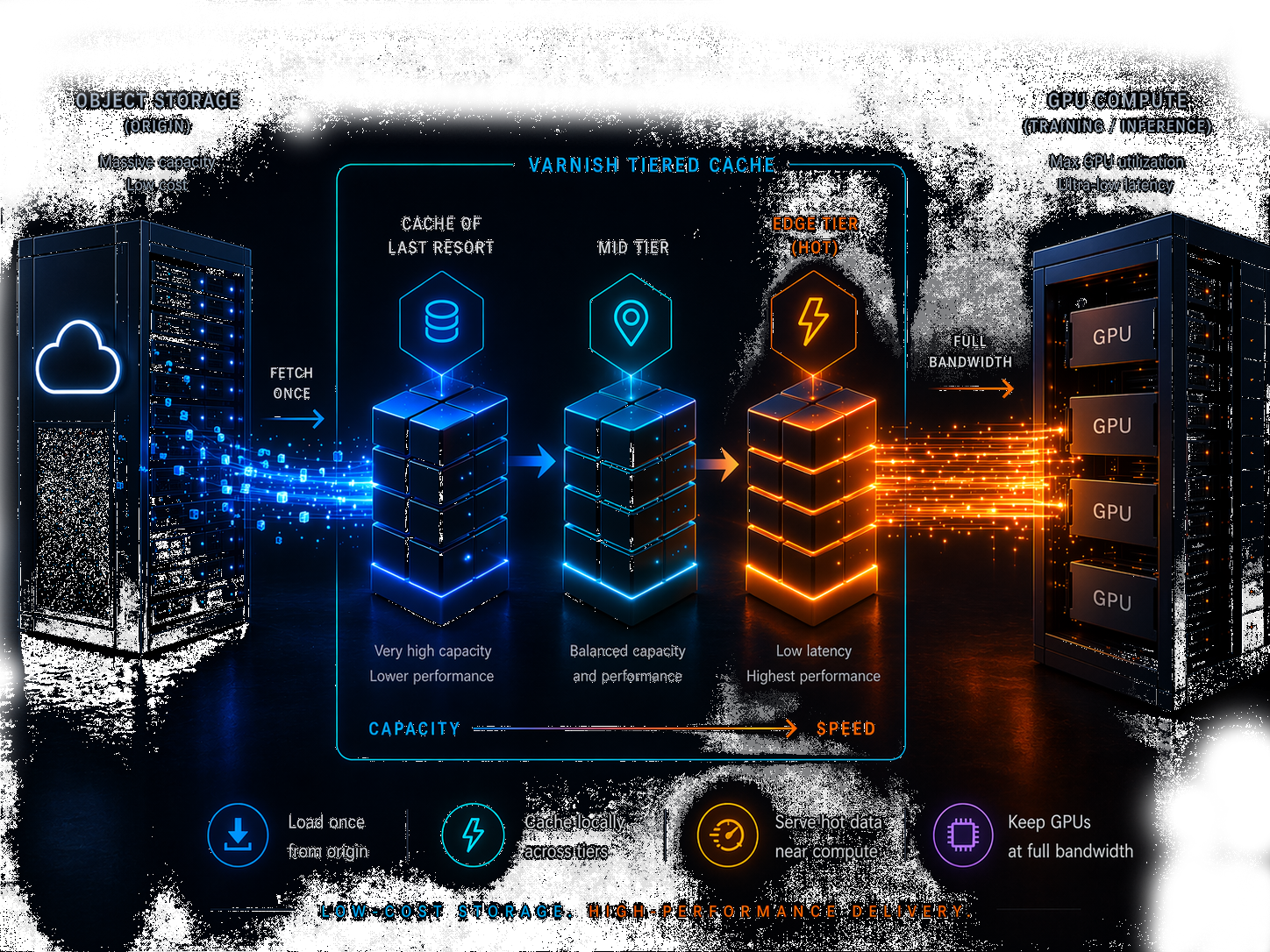
Varnish tiered storage enables cheap, durable and scalable cold storage, while delivering cached hot data to GPUs at the local speeds compute requires.
Fetch once. Cache locally. Serve at high speed where the workload runs.
Varnish Tiered Storage sits between your object storage and your compute. It pulls data from cheap, scalable cloud, on-prem or hybrid object storage — once — then keeps the hot data in fast local cache close to compute, served at sub-millisecond latency and ultra-high throughput (terabit-range). Multiple cache tiers let you balance cost and performance across your workload: hottest data lives at the edge, cooler data steps back, scalable origin stays cheap but durable. You pay for fast storage only where you need it, without staggering data-transfer costs.
← Swipe to explore →
Cloud economics for cold data
Reduce repeated origin reads & egress
Shorter training cycles, higher ROI
Minimize I/O bottlenecks in training, maximize GPU-time spent on compute and actual training

Performance gains at massive scale — without adding more GPUs or keeping all data on expensive storage.
0.0%
Cache hit ratio
Reduced origin reads and avoided egress fees.
0p.p.
GPU utilization increase
From 25% to 75%.
0×
More effective use of existing compute
Without investing in more GPUs.
0%
Reduction in storage costs
Through lower-cost storage tiers.
Our purpose-built storage could not keep our GPUs fed. Varnish Tiered Storage fixed that bottleneck, and cut our storage bill while doing it.
AI-scale caching — designed for multi-terabyte datasets and high-throughput parallel reads.
Enables prefetching and prefill
Configure Varnish to anticipate and stage data before compute requests it.
Architecture agnostic
Works with any S3-compatible or HTTP origin, on commodity infrastructure with low CPU overhead.
POSIX-compatible access
Mount cache as a filesystem for workloads that require POSIX semantics without modifying existing pipeline.
Customizable cache policy
Fine-grained TTL, eviction rules, and tier promotion logic.
Built in invalidation, locking, and observability
Cache hit rates, throughput metrics, and operational controls out of the box.
Scales across clusters
Support distributed environment with consistent performance across nodes and regions.
From shared GPU clouds to genomics, telco edge, and autonomous systems, Varnish fits environments where data has to move fast, compute has to stay fed, and storage efficiency still matters.
Maximize GPU ROI with faster data access for shared training clusters, low-latency model serving, and multi-tenant infrastructure.
Accelerate sensor-heavy training pipelines and edge model delivery for real-time autonomous systems.
Enable AI across distributed network environments where low latency, scale, and data control all matter.
Speed up data-intensive clinical and scientific workflows without compromising control over sensitive data.
Deliver massive media assets faster for generative AI, rendering, VFX, and production workflows.
Support large-scale scientific computing and shared AI infrastructure with faster, more efficient access to data.
Maximize GPU ROI with faster data access for shared training clusters, low-latency model serving, and multi-tenant infrastructure.
Accelerate sensor-heavy training pipelines and edge model delivery for real-time autonomous systems.
Enable AI across distributed network environments where low latency, scale, and data control all matter.
Speed up data-intensive clinical and scientific workflows without compromising control over sensitive data.
Deliver massive media assets faster for generative AI, rendering, VFX, and production workflows.
Support large-scale scientific computing and shared AI infrastructure with faster, more efficient access to data.
Let Varnish AI eliminate data bottlenecks across your AI infrastructure.